圖文/鏡週刊
7月18日是英國小說家珍奧斯汀(Jane Austen)逝世兩百週年的日子。
她的作品膾炙人口,關於她的研究汗牛充棟。研讀英國文學,很多人也都是從她的《理性與感性》、《傲慢與偏見》想像小說應有的樣子。
如今拜科技之賜,有人想透過數據分析奧斯汀的用詞遣字,理解她小說魅力歷久不衰的秘密。
珍奧斯汀過世兩百年後,她的文字仍主導著龐大的文化產業。
從戲劇和電影的改編、同人小說(fan fiction,也就是利用類似角色情節場景做的二次創作)、相關文創商品、甚至旅遊行程,都圍繞著她和她的幾部小說。
她歷久不衰的魅力何在?她的文字有哪些她同輩作家不及之處?

美國史丹佛大學文學實驗室創辦人莫瑞提(Franco Moretti),專研用數據分析進行小說的研究,他認為某些作品之所以能歷經時間的考驗而成為經典,仰賴的是普通讀者的選擇。這種過程。類似於生物學物競天擇的演化。
文學史的形成,是因為讀者喜歡文學作品中顯著的特徵而做出了選擇,讓它跨越世代存活。
莫瑞提,美國史丹佛大學文學實驗室創辦人
那麼,讓奧斯汀顯得不凡的特徵是什麼,它們能否透過數據來衡量?我們能否用數據描繪出文學的天才?
紐約時報的兩名動態圖表編輯Kathleen A. Flynn和Josh Katz,最近在 Upshot 專欄裡發表了分析的結果。
奧斯汀的小說成就斐然,她寫作的創新之處,或許未完全受到和她同時代人們的理解。不過,她小說較早被注意到一個特色,是文字上自然主義的風格。
不同於奧斯汀當時風行的作品,她的場景沒有充滿鬼影幢幢的義大利古堡(她在《諾桑覺寺》裡曾經嘲笑哥德式小說的鬼怪設計)、沒有如《Clarissa》裡主角被浪蕩公子綁架、或《Cecelia》女主角繼承了附加怪異條件的遺產的這類懸疑情節。當時的歷史小說家史考特(Walter Scott)曾經讚美奧斯汀「取法自然的藝術,她彷彿真實存在市井小民的日常中並傳達給讀者,而不是出自想像的世界的華麗場景。」
紐約時報想要透過數據,繪出奧斯汀的自然主義的長相。
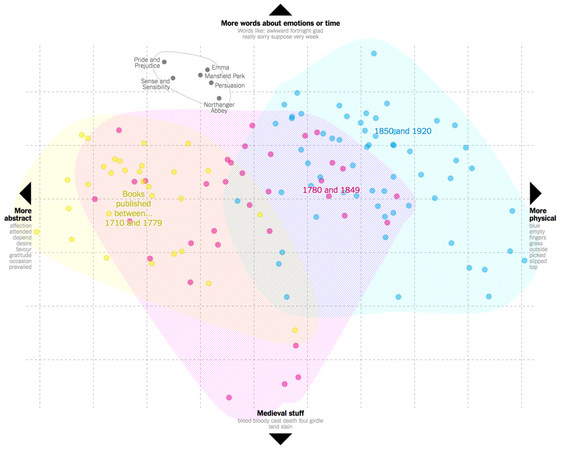
紐約時報選取的分析對象,是奧斯汀的六本小說,和125部出版於1710年到1920年之間的英語小說。它利用統計學的「主成份分析」技術,依據每一個作品使用的詞彙設計了一個平面的圖表。使用的字詞越相近的書,在圖上的位置就會越靠近。
根據這兩位研究者的說法,在水平軸上,越靠左側的是較抽象的,與心理狀態或社交關係相關字詞,例如:acquaintance(熟人)、affection(情感)、attended(出席)、conduct(舉止)、depended(依賴)、desire(慾望)、endeavoured(努力)、favour(喜愛)、gratitude(感謝)、indulgence(放縱)、merit(價值)、obliged(責任)、occasion(機緣)、prevailed(勝出)、received(接受)、resentment(憎恨)、resolution(決心)、resolved(堅定)、suffered(受苦)和virtue(美德)。
越是靠右邊,則是較具體的,與實體世界和感官知覺有關的,例如:blue(藍色)、close(接近)、dark(黑暗)、edge(邊緣)、empty(空洞)、fingers(指頭)、grass(草地)、head(頭)、hot(熱)、outside(外面)、picked(挑選)、rolled(滾動)、round(圓)、shoulder(肩膀)、slipped(滑動)、slowly(緩慢)、stand(站立)、top(頂端)、watch(錶)和white(白色)。
至於在圖表的垂直軸,越往下是越類似中世紀通俗劇用到的英文,例如banquet(宴席)、beheld(看)、slain(殺)、sword(劍)、thee(你)。
而圖表往上,則是一些日常性的用詞,強調或比較的副詞像是quite(相當)、really(真的)、very(非常),以及與時間和情緒有關的詞:always(總是)、fortnight(兩星期)、week(星期)、awkward(笨拙)、decided(決定)、dislike(不喜愛)、glad(高興)、sorry(難過)、suppose(設想)。
從這張圖表來看,奧斯汀幾乎是自成一格。她的六部小說(《傲慢與偏見》、《理性與感性》、《愛瑪》、《曼菲德公園》、《說服》、《諾桑覺寺》)全部集中在圖的左上角。
根據研究者的分析,這張圖表顯示奧斯汀小說裡使用的詞,顯然是抽象的多過於實體的描述,而日常情境的用語也多於以中世紀為場景的通俗劇詞彙。
從數據的分析看得出珍奧斯汀的小說用詞遣字有一些習慣的用語。但這是否就代表作家的個人風格?此外,光憑這個圖表,是否就足以說明小說歷久不衰、躍居經典的原因?
紐時的研究員認為,或許我們需要更多的數據。
在另一項分析珍奧斯汀小說用字的研究報告中,它拿來與一批同時期英國小說以及1780年到1820年之間的小說做比較。
它發現了奧斯汀的用詞幾個明確的特點。
比如說,和其他同期作家相比,她使用了相對較多指涉女性的字如she、 her(她、她的)、 Miss(小姐)和sister(姊妹),這結果如果考量奧斯汀的小說主題,其實不難設想。另外,奧斯汀使用比例比其他作家更高的是一些強調作用的修飾字:像是very(非常)、much(很多)、so(如此)。這種強調詞的使用,與她寫作的一個重要特徵有關聯,而且這個特徵乍看之下很難用量化的方式分析,那就是反諷(irony)。
紐時的報導中提到,傳統上對奧斯汀的研究,多半會注意到她作品中「表象與本質之間的不相稱」。在小說裡頻繁使用「very」這個字的段落,往往可以察覺出它所說的字面的意思往往和實際的意思相衝突,這種誇飾強調正好微妙導引讀者去懷疑,明白一切並非字面看來。而這種反諷的手法,如今透過量化的數據分析,竟然也可以得到佐證。
紐約時報的分析,或許可以歸類為隨著數據研究而興起的「文學的統計學研究」。過去最知名的是數據記者Ben Blatt的研究,他發現雷布萊伯利(Ray Bradbury,《華氏451》的作者)小說經常出現的詞是cinnamon(肉桂),小說家納博科夫(Vladimir Nabokov)最喜歡的字是mauve(錦葵),而托爾金的《哈比人》裡面,she這個字總共竟只出現一次。
這些分析結果,在一般人看來或許只是一些文學冷知識,學院傳統裡的學者也可能認為它無關宏旨。不過,它確實也帶動了文學研究的一些改變。
去年牛津大學出版社,透過字詞的數據分析後,決定把莎士比亞同時代的作家馬羅,列為莎翁名劇《亨利六世》的共同作者,成了震動莎翁研究的大新聞。
所以,這些看似無關文字、風格的統計數字,對於一個文學名著(或是失敗的作品)是如何構成的,或許提供了讀者不同面向的理解。
參考資料:
The Word Choices That Explain Why Jane Austen Endures(New York Times)
A journalist uses statistics to uncover authors' "cinnamon words"(PRI)
更多鏡週刊報導
牛津開新例 莎翁名劇增列共同作者
夜空下的GDP密碼 三名美國經濟學家破解中國數據之謎
聽見金融海嘯的聲音... 網路新工具將圖表化為鋼琴音階








讀者迴響